Computing 'basic' structure characteristics

Hi again Chimera Team, I have 2 questions, one specific and one quite general. If you see the emails below, I was speaking with Jaime about computing basic structure characteristics (pKa, net surface charge, proportions/predominance of 2ary structure etc). The general question I have is what suggestions might you have for functions within chimera capable of computing any or all of these features? (ideally commandline based so that I can run this over many PDB structures). The specific question that pertains to the below is that Jaime mentioned each residue has an int value that corresponds to a particular structure designation, ints from -1 to 6. Could you let me know what the correspondence is between these values and actual structure? Joe Healey M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk Jointly working in: Waterfield Lab<http://www2.warwick.ac.uk/fac/med/research/tsm/microinfect/staff/waterfieldl...> (WMS Microbiology and Infection Unit) and the Gibson Lab<http://www2.warwick.ac.uk/fac/sci/chemistry/research/gibson/gibsongroup/> (Warwick Chemistry) Twitter: @JRJHealey<https://twitter.com/JRJHealey> | Website: MOAC Page<http://www2.warwick.ac.uk/fac/sci/moac/people/students/2013/joseph_healey> ________________________________ From: Jaime Rodríguez-Guerra <jaime.rodriguezguerra@uab.cat> Sent: 08 October 2016 09:55 To: Healey, Joe Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers Hi again Joe! No problem at all; I'll be pleased to help you. For charges, I think Chimera can calculate them as part of the Surface/Binding analysis> Dock Prep wizard. You also have some information about 2nd structure inside chimera.Residue objects, specifically ssId attribute. However, these are int values, and I don't really know which ss is each (ranging from -1 to 6, as I have observed). For pKa, you can use PropKa (https://github.com/jensengroup/propka-3.1), and then I guess you'll be able to get the pI somewhere around the code. I've been designing a GUI to use this in Chimera, but it's not yet ready... Sorry about that! I don't know if you need anything else... but I think the Python community will have you covered one way or another! BioPython.PDB might be useful too (http://biopython.org/wiki/The_Biopython_Structural_Bioinformatics_FAQ). Cheers, Jaime. 2016-10-06 15:57 GMT+02:00 Healey, Joe <J.R.J.Healey@warwick.ac.uk<mailto:J.R.J.Healey@warwick.ac.uk>>: Hi again Jaime, Hope you don't mind but I had a couple of questions for you. You may have figured out from all the previous correspondance that I have a load of protein structure simulations. The RMSD script you helped me with was to sort of 'broadly' gauge whether the simulations looked realistic or not. For some of them, I'd like to build up a chart of their tertiary structure properties based on the simulations. Things like charge/hydrophobicity, isoelectric point, 2ndary structure dominance and so on. Could I ask you for any advice you might about what tools are available to analyse PDBs? I'm sure chimera is probably capable of it too. I've mostly found webservers at the moment for specific tasks, but I'd like to do most of the analysis locally. My group is full of bioinformaticians, but I'm the only one who really looks at proteins so I need the advice of a computational chemist I think! Cheers, Joe Joe Healey M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620<tel:%2B44%20%280%29%207536%20042620> | Email: J.R.J.Healey@warwick.ac.uk<mailto:J.R.J.Healey@warwick.ac.uk> Jointly working in: Waterfield Lab<http://www2.warwick.ac.uk/fac/med/research/tsm/microinfect/staff/waterfieldl...> (WMS Microbiology and Infection Unit) and the Gibson Lab<http://www2.warwick.ac.uk/fac/sci/chemistry/research/gibson/gibsongroup/> (Warwick Chemistry) Twitter: @JRJHealey<https://twitter.com/JRJHealey> | Website: MOAC Page<http://www2.warwick.ac.uk/fac/sci/moac/people/students/2013/joseph_healey> ________________________________ From: Healey, Joe Sent: 23 September 2016 11:51:40 To: Jaime Rodríguez-Guerra Cc: Eric Pettersen; chimera-users@cgl.ucsf.edu<mailto:chimera-users@cgl.ucsf.edu> Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers Not at all! Much appreciated, as I think I mentioned, this is my first go at writing anything remotely complex in python (and not a bad turn out for about a week I don't think...) A lot of the mess comes from copying functional bits from StackOverflow in the interests of just getting it working first, and making it pretty second as I'm sure you can appreciate (you'd hate to see my LaTeX preamble)! Not needed to close the file with 'with' is useful to know (takes some of the headache out of knowing where to place the close). I'll certainly make the tidy ups you've suggested, for my own learning. Thanks again, Joe :) Joe Healey M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620<tel:%2B44%20%280%29%207536%20042620> | Email: J.R.J.Healey@warwick.ac.uk<mailto:J.R.J.Healey@warwick.ac.uk> Jointly working in: Waterfield Lab<http://www2.warwick.ac.uk/fac/med/research/tsm/microinfect/staff/waterfieldl...> (WMS Microbiology and Infection Unit) and the Gibson Lab<http://www2.warwick.ac.uk/fac/sci/chemistry/research/gibson/gibsongroup/> (Warwick Chemistry) Twitter: @JRJHealey<https://twitter.com/JRJHealey> | Website: MOAC Page<http://www2.warwick.ac.uk/fac/sci/moac/people/students/2013/joseph_healey> ________________________________ From: Jaime Rodríguez-Guerra <jaime.rodriguezguerra@uab.cat<mailto:jaime.rodriguezguerra@uab.cat>> Sent: 23 September 2016 10:56:38 To: Healey, Joe Cc: Eric Pettersen; Jaime Rodríguez-Guerra; chimera-users@cgl.ucsf.edu<mailto:chimera-users@cgl.ucsf.edu> Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers Hi Joe! You're welcome! Glad to see you got it working. I've reviewed your code and would want to point out some details that might be helpful to you in the future, though. These are mostly style-related things, but those will contribute to a cleaner reading experience! 1. You don't need backslashes if you're inside parenthesis. So, in all those parse_argument lines, you can safely delete them. Related to this, you can wrap imports with parenthesis, so that backslashes are not needed. 2. Tuple unpacking does not need parenthesis in you're dealing with 1D-tuples. Only needed if you are dealing with more than one dimension (ie, (animal, fruit), sport = [['tiger', 'pear'], 'soccer'] 3. Since you are opening files with the "with" context manager, you don't need to manually close the file later. It's closed automatically as soon as you leave that with block. 4. Lines 166-170 could be replaced with a (cleaner, but not necessarily more performant) glob.glob() call. Check it out to see if it satisfies your requirements. 5. While you are at it, take a look at the PEP8 docs and the Google Python style guide. You don't need to follow all the rules, but they are really helpful in bringing consistency to your own style! That's it! Hope you don't mind these pieces of advice :) Cheers, Jaime. 2016-09-23 11:27 GMT+02:00 Healey, Joe <J.R.J.Healey@warwick.ac.uk<mailto:J.R.J.Healey@warwick.ac.uk>>:
That was exactly what I was after thanks! I figured the object orientation should provide that somewhere but was barking up slightly the wrong tree!
Thank you all for all your help - definitely wouldn't have been able to do it without you!
If it's of any interest, or it helps for any future questions where you might want to refer back to code segments, I've put the more-or-less-finished script in this paste:
Joe Healey
M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620<tel:%2B44%20%280%29%207536%20042620> | Email: J.R.J.Healey@warwick.ac.uk<mailto:J.R.J.Healey@warwick.ac.uk>
Jointly working in: Waterfield Lab (WMS Microbiology and Infection Unit) and the Gibson Lab (Warwick Chemistry)
Twitter: @JRJHealey | Website: MOAC Page ________________________________ From: Eric Pettersen <pett@cgl.ucsf.edu<mailto:pett@cgl.ucsf.edu>> Sent: 22 September 2016 20:54:35 To: Jaime Rodríguez-Guerra Cc: chimera-users@cgl.ucsf.edu<mailto:chimera-users@cgl.ucsf.edu>; Healey, Joe Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers
Thanks Jaime — exactly right. I realized that the “atoms1, atoms2” in my original example didn’t really give any indication of which atoms were which, which is why in my later examples I changed to "simAtoms, refAtoms”, so it’s actually “atoms2” that are the reference atoms.
—Eric
On Sep 22, 2016, at 11:45 AM, Jaime Rodríguez-Guerra <jaime.rodriguezguerra@uab.cat<mailto:jaime.rodriguezguerra@uab.cat>> wrote:
Hi!
Since you are getting lists of atoms back, you only need to do some attribute access (rather than method calling)!
Every chimera.Atom object has an attribute called molecule: a reference to its parent chimera.Molecule. chimera.Molecule objects have an attribute called 'name', but sometimes this is not very informative (depends on your input), so you need to resort to the pdb filename, stored in the first element of the openedAs tuple.
In code, this looks like this:
for atoms1, atoms2, rmsd, fullRmsd in match(CP_BEST, [ref, sims], defaults[MATRIX], "nw", defaults[GAP_OPEN], defaults[GAP_EXTEND]): molecule1 = atoms1[0].molecule # any atom from the list will do molecule2 = atoms2[0].molecule print molecule1.name<http://molecule1.name>, "\t", molecule2.name<http://molecule2.name>, "\t", rmsd # molecule1.openedAs[0] will also work here
I don't know if atoms1 comes consistently from the reference molecule, but I'd guess it does.
Hope it helps! _______________________________________________ Chimera-users mailing list: Chimera-users@cgl.ucsf.edu<mailto:Chimera-users@cgl.ucsf.edu> Manage subscription: http://plato.cgl.ucsf.edu/mailman/listinfo/chimera-users

Hi Joe, Chimera has “addcharge” or “pqr” commands for associating atoms with charges and “apbs” to run Poisson-Boltzmann electrostatic calculations and return an electrostatic potential (ESP) map for surface coloring. The latter two actually call welb services. There is also a “coulombic” command for coloring surfaces by Coulombic (instead of Poisson-Boltzmann) ESP. These are also all available as tools with graphical interfaces, but you mentioned scripting so I listed the commands. However, I don’t know what you mean by surface charge, but unless you meant ESP Chimera does not calculate it, nor does it predict pKa. As Jaime said, you can use ProPka (he also gave an URL… hey Jaime, we’re excited to hear you might write a Chimera interface for this!). If you just want to look at predominance of secondary structures, you would not use those integers which mean first strand, second strand, first helix, etc. Instead you could just see how many residues are already assigned as strand, helix, and coil. There aren’t commands to do this directly, only some very cumbersome approaches that I imagine are vastly inferior to using Python (like “select strand” and then writing a list of all those residues with “writesel” etc.). I can’t help with the Python side, this is just the perspective from the commands side. All the commands I mentioned are documented, <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html> Best, Elaine ----- Elaine C. Meng, Ph.D. UCSF Computer Graphics Lab (Chimera team) and Babbitt Lab Department of Pharmaceutical Chemistry University of California, San Francisco On Oct 8, 2016, at 8:38 AM, Healey, Joe <J.R.J.Healey@warwick.ac.uk> wrote:
Hi again Chimera Team,
I have 2 questions, one specific and one quite general. If you see the emails below, I was speaking with Jaime about computing basic structure characteristics (pKa, net surface charge, proportions/predominance of 2ary structure etc).
The general question I have is what suggestions might you have for functions within chimera capable of computing any or all of these features? (ideally commandline based so that I can run this over many PDB structures).
The specific question that pertains to the below is that Jaime mentioned each residue has an int value that corresponds to a particular structure designation, ints from -1 to 6. Could you let me know what the correspondence is between these values and actual structure?
Joe Healey
M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk
Jointly working in: Waterfield Lab (WMS Microbiology and Infection Unit) and the Gibson Lab (Warwick Chemistry)
Twitter: @JRJHealey | Website: MOAC Page
From: Jaime Rodríguez-Guerra <jaime.rodriguezguerra@uab.cat> Sent: 08 October 2016 09:55 To: Healey, Joe Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers
Hi again Joe!
No problem at all; I'll be pleased to help you.
For charges, I think Chimera can calculate them as part of the Surface/Binding analysis> Dock Prep wizard. You also have some information about 2nd structure inside chimera.Residue objects, specifically ssId attribute. However, these are int values, and I don't really know which ss is each (ranging from -1 to 6, as I have observed).
For pKa, you can use PropKa (https://github.com/jensengroup/propka-3.1), and then I guess you'll be able to get the pI somewhere around the code. I've been designing a GUI to use this in Chimera, but it's not yet ready... Sorry about that!
I don't know if you need anything else... but I think the Python community will have you covered one way or another! BioPython.PDB might be useful too (http://biopython.org/wiki/The_Biopython_Structural_Bioinformatics_FAQ).
Cheers, Jaime.
2016-10-06 15:57 GMT+02:00 Healey, Joe <J.R.J.Healey@warwick.ac.uk>: Hi again Jaime,
Hope you don't mind but I had a couple of questions for you. You may have figured out from all the previous correspondance that I have a load of protein structure simulations. The RMSD script you helped me with was to sort of 'broadly' gauge whether the simulations looked realistic or not.
For some of them, I'd like to build up a chart of their tertiary structure properties based on the simulations. Things like charge/hydrophobicity, isoelectric point, 2ndary structure dominance and so on.
Could I ask you for any advice you might about what tools are available to analyse PDBs? I'm sure chimera is probably capable of it too. I've mostly found webservers at the moment for specific tasks, but I'd like to do most of the analysis locally. My group is full of bioinformaticians, but I'm the only one who really looks at proteins so I need the advice of a computational chemist I think!
Cheers,
Joe
Joe Healey
M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk
Jointly working in: Waterfield Lab (WMS Microbiology and Infection Unit) and the Gibson Lab (Warwick Chemistry)
Twitter: @JRJHealey | Website: MOAC Page From: Healey, Joe Sent: 23 September 2016 11:51:40 To: Jaime Rodríguez-Guerra Cc: Eric Pettersen; chimera-users@cgl.ucsf.edu
Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers
Not at all! Much appreciated, as I think I mentioned, this is my first go at writing anything remotely complex in python (and not a bad turn out for about a week I don't think...)
A lot of the mess comes from copying functional bits from StackOverflow in the interests of just getting it working first, and making it pretty second as I'm sure you can appreciate (you'd hate to see my LaTeX preamble)!
Not needed to close the file with 'with' is useful to know (takes some of the headache out of knowing where to place the close).
I'll certainly make the tidy ups you've suggested, for my own learning.
Thanks again,
Joe :)
Joe Healey
M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk
Jointly working in: Waterfield Lab (WMS Microbiology and Infection Unit) and the Gibson Lab (Warwick Chemistry)
Twitter: @JRJHealey | Website: MOAC Page From: Jaime Rodríguez-Guerra <jaime.rodriguezguerra@uab.cat> Sent: 23 September 2016 10:56:38 To: Healey, Joe Cc: Eric Pettersen; Jaime Rodríguez-Guerra; chimera-users@cgl.ucsf.edu Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers
Hi Joe!
You're welcome! Glad to see you got it working. I've reviewed your code and would want to point out some details that might be helpful to you in the future, though. These are mostly style-related things, but those will contribute to a cleaner reading experience!
1. You don't need backslashes if you're inside parenthesis. So, in all those parse_argument lines, you can safely delete them. Related to this, you can wrap imports with parenthesis, so that backslashes are not needed. 2. Tuple unpacking does not need parenthesis in you're dealing with 1D-tuples. Only needed if you are dealing with more than one dimension (ie, (animal, fruit), sport = [['tiger', 'pear'], 'soccer'] 3. Since you are opening files with the "with" context manager, you don't need to manually close the file later. It's closed automatically as soon as you leave that with block. 4. Lines 166-170 could be replaced with a (cleaner, but not necessarily more performant) glob.glob() call. Check it out to see if it satisfies your requirements. 5. While you are at it, take a look at the PEP8 docs and the Google Python style guide. You don't need to follow all the rules, but they are really helpful in bringing consistency to your own style!
That's it! Hope you don't mind these pieces of advice :)
Cheers, Jaime.
2016-09-23 11:27 GMT+02:00 Healey, Joe <J.R.J.Healey@warwick.ac.uk>:
That was exactly what I was after thanks! I figured the object orientation should provide that somewhere but was barking up slightly the wrong tree!
Thank you all for all your help - definitely wouldn't have been able to do it without you!
If it's of any interest, or it helps for any future questions where you might want to refer back to code segments, I've put the more-or-less-finished script in this paste:
Joe Healey
M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk
Jointly working in: Waterfield Lab (WMS Microbiology and Infection Unit) and the Gibson Lab (Warwick Chemistry)
Twitter: @JRJHealey | Website: MOAC Page ________________________________ From: Eric Pettersen <pett@cgl.ucsf.edu> Sent: 22 September 2016 20:54:35 To: Jaime Rodríguez-Guerra Cc: chimera-users@cgl.ucsf.edu; Healey, Joe Subject: Re: [Chimera-users] Recursive structure matching and acquisition of descriptive numbers
Thanks Jaime — exactly right. I realized that the “atoms1, atoms2” in my original example didn’t really give any indication of which atoms were which, which is why in my later examples I changed to "simAtoms, refAtoms”, so it’s actually “atoms2” that are the reference atoms.
—Eric
On Sep 22, 2016, at 11:45 AM, Jaime Rodríguez-Guerra <jaime.rodriguezguerra@uab.cat> wrote:
Hi!
Since you are getting lists of atoms back, you only need to do some attribute access (rather than method calling)!
Every chimera.Atom object has an attribute called molecule: a reference to its parent chimera.Molecule. chimera.Molecule objects have an attribute called 'name', but sometimes this is not very informative (depends on your input), so you need to resort to the pdb filename, stored in the first element of the openedAs tuple.
In code, this looks like this:
for atoms1, atoms2, rmsd, fullRmsd in match(CP_BEST, [ref, sims], defaults[MATRIX], "nw", defaults[GAP_OPEN], defaults[GAP_EXTEND]): molecule1 = atoms1[0].molecule # any atom from the list will do molecule2 = atoms2[0].molecule print molecule1.name, "\t", molecule2.name, "\t", rmsd # molecule1.openedAs[0] will also work here
I don't know if atoms1 comes consistently from the reference molecule, but I'd guess it does.
Hope it helps! _______________________________________________ Chimera-users mailing list: Chimera-users@cgl.ucsf.edu Manage subscription: http://plato.cgl.ucsf.edu/mailman/listinfo/chimera-users
_______________________________________________ Chimera-users mailing list: Chimera-users@cgl.ucsf.edu Manage subscription: http://plato.cgl.ucsf.edu/mailman/listinfo/chimera-users
On Oct 9, 2016, at 9:53 AM, Elaine Meng <meng@cgl.ucsf.edu> wrote:
Hi Joe, Chimera has “addcharge” or “pqr” commands for associating atoms with charges…
Small correction: should be “pdb2pqr” instead of “pqr” <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html> Elaine

On Oct 9, 2016, at 9:53 AM, Elaine Meng <meng@cgl.ucsf.edu> wrote:
If you just want to look at predominance of secondary structures, you would not use those integers which mean first strand, second strand, first helix, etc. Instead you could just see how many residues are already assigned as strand, helix, and coil. There aren’t commands to do this directly, only some very cumbersome approaches that I imagine are vastly inferior to using Python (like “select strand” and then writing a list of all those residues with “writesel” etc.).
I can’t help with the Python side, this is just the perspective from the commands side. All the commands I mentioned are documented, <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html>>
To supplement this part of the answer, you can loop through a bunch of PDB files in Python as outlined here: http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html <http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html> You can determine the fraction of residues in helix and sheet with code like this: from chimera import openModels, Molecule #… inside the loop… for mol in openModels.list(modelTypes=[Molecule]): sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) # write them to a file with “print>>f” or to the reply log with just “print” The above assumes you have a little bit of familiarity with Python. I can provide more explanation if you need it. —Eric Eric Pettersen UCSF Computer Graphics Lab
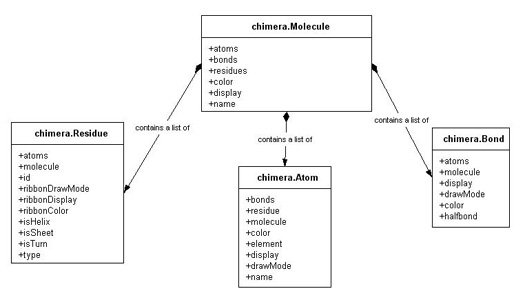
That looks spot on thanks Eric. Does chimera specify anything other than "isHelix"/"isSheet"/"isTurn"? I can see these in chimera's object model (stole your image below!). Is disordered sequence treated differently or just as Turn in Chimera? I'll run this through the commandline with Jaime's pychimera (a real game changer for me!) so creating output files I'll probably just handle with piping STDOUT. [cid:bae07725-f281-4ce3-a9f2-72666f911e0b] Thanks, Joe Joe Healey M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk Jointly working in: Waterfield Lab<http://www2.warwick.ac.uk/fac/med/research/tsm/microinfect/staff/waterfieldl...> (WMS Microbiology and Infection Unit) and the Gibson Lab<http://www2.warwick.ac.uk/fac/sci/chemistry/research/gibson/gibsongroup/> (Warwick Chemistry) Twitter: @JRJHealey<https://twitter.com/JRJHealey> | Website: MOAC Page<http://www2.warwick.ac.uk/fac/sci/moac/people/students/2013/joseph_healey> ________________________________ From: Eric Pettersen <pett@cgl.ucsf.edu> Sent: 10 October 2016 18:54:08 To: Healey, Joe Cc: chimera List Subject: Re: [Chimera-users] Computing 'basic' structure characteristics On Oct 9, 2016, at 9:53 AM, Elaine Meng <meng@cgl.ucsf.edu<mailto:meng@cgl.ucsf.edu>> wrote: If you just want to look at predominance of secondary structures, you would not use those integers which mean first strand, second strand, first helix, etc. Instead you could just see how many residues are already assigned as strand, helix, and coil. There aren't commands to do this directly, only some very cumbersome approaches that I imagine are vastly inferior to using Python (like "select strand" and then writing a list of all those residues with "writesel" etc.). I can't help with the Python side, this is just the perspective from the commands side. All the commands I mentioned are documented, <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html> To supplement this part of the answer, you can loop through a bunch of PDB files in Python as outlined here: http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html You can determine the fraction of residues in helix and sheet with code like this: from chimera import openModels, Molecule #... inside the loop... for mol in openModels.list(modelTypes=[Molecule]): sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) # write them to a file with "print>>f" or to the reply log with just "print" The above assumes you have a little bit of familiarity with Python. I can provide more explanation if you need it. -Eric Eric Pettersen UCSF Computer Graphics Lab
{kind=link}
Hi Joe, Back in the day, when that diagram was created, the PDB had TURN records which defined the location of various specific turn types (hairpin, etc.). That’s what “isTurn” indicated, not just all non-helix/sheet. Eventually the PDB dropped support for TURN records, and the isTurn attribute went the way of the dodo — we removed it. —Eric
On Oct 11, 2016, at 2:29 AM, Healey, Joe <J.R.J.Healey@warwick.ac.uk> wrote:
That looks spot on thanks Eric.
Does chimera specify anything other than "isHelix"/"isSheet"/"isTurn"?
I can see these in chimera's object model (stole your image below!). Is disordered sequence treated differently or just as Turn in Chimera?
I'll run this through the commandline with Jaime's pychimera (a real game changer for me!) so creating output files I'll probably just handle with piping STDOUT.
<pastedImage.png> Thanks,
Joe
Joe Healey
M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk <mailto:J.R.J.Healey@warwick.ac.uk>
Jointly working in: Waterfield Lab <http://www2.warwick.ac.uk/fac/med/research/tsm/microinfect/staff/waterfieldl...> (WMS Microbiology and Infection Unit) and the Gibson Lab <http://www2.warwick.ac.uk/fac/sci/chemistry/research/gibson/gibsongroup/> (Warwick Chemistry)
Twitter: @JRJHealey <https://twitter.com/JRJHealey> | Website: MOAC Page <http://www2.warwick.ac.uk/fac/sci/moac/people/students/2013/joseph_healey> From: Eric Pettersen <pett@cgl.ucsf.edu> Sent: 10 October 2016 18:54:08 To: Healey, Joe Cc: chimera List Subject: Re: [Chimera-users] Computing 'basic' structure characteristics
On Oct 9, 2016, at 9:53 AM, Elaine Meng <meng@cgl.ucsf.edu <mailto:meng@cgl.ucsf.edu>> wrote:
If you just want to look at predominance of secondary structures, you would not use those integers which mean first strand, second strand, first helix, etc. Instead you could just see how many residues are already assigned as strand, helix, and coil. There aren’t commands to do this directly, only some very cumbersome approaches that I imagine are vastly inferior to using Python (like “select strand” and then writing a list of all those residues with “writesel” etc.).
I can’t help with the Python side, this is just the perspective from the commands side. All the commands I mentioned are documented, <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html>>
To supplement this part of the answer, you can loop through a bunch of PDB files in Python as outlined here:
http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html <http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html>
You can determine the fraction of residues in helix and sheet with code like this:
from chimera import openModels, Molecule
#… inside the loop… for mol in openModels.list(modelTypes=[Molecule]): sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) # write them to a file with “print>>f” or to the reply log with just “print”
The above assumes you have a little bit of familiarity with Python. I can provide more explanation if you need it.
—Eric
Eric Pettersen UCSF Computer Graphics Lab
Nevermind, I think you can ignore my last email. Chimera wasn't recognising the 'isTurn' attribute so I guess that's my answer. I'll just define turn/other as 1-(everything else) which should suffice. I've got the following based on your snippet, but for some reason it is giving me zeros for helix and turn: chimera.openModels.open(args.infile,type="PDB") with open(args.outfile, "w") as outputFile: for mol in openModels.list(modelTypes=[Molecule]): helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) other_fract = (1 - (helix_fract + sheet_fract)) print(args.infile + "\t" + str(helix_fract) + "\t" + str(sheet_fract) + "\t" + str(other_fract)) outputFile.write(args.infile + "\t" + str(helix_fract) + "\t" + str(sheet_fract) + "\t" + str(other_fract) + "\n") What am I missing here? Thanks Joe Joe Healey M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk Jointly working in: Waterfield Lab<http://www2.warwick.ac.uk/fac/med/research/tsm/microinfect/staff/waterfieldl...> (WMS Microbiology and Infection Unit) and the Gibson Lab<http://www2.warwick.ac.uk/fac/sci/chemistry/research/gibson/gibsongroup/> (Warwick Chemistry) Twitter: @JRJHealey<https://twitter.com/JRJHealey> | Website: MOAC Page<http://www2.warwick.ac.uk/fac/sci/moac/people/students/2013/joseph_healey> ________________________________ From: Eric Pettersen <pett@cgl.ucsf.edu> Sent: 10 October 2016 18:54:08 To: Healey, Joe Cc: chimera List Subject: Re: [Chimera-users] Computing 'basic' structure characteristics On Oct 9, 2016, at 9:53 AM, Elaine Meng <meng@cgl.ucsf.edu<mailto:meng@cgl.ucsf.edu>> wrote: If you just want to look at predominance of secondary structures, you would not use those integers which mean first strand, second strand, first helix, etc. Instead you could just see how many residues are already assigned as strand, helix, and coil. There aren't commands to do this directly, only some very cumbersome approaches that I imagine are vastly inferior to using Python (like "select strand" and then writing a list of all those residues with "writesel" etc.). I can't help with the Python side, this is just the perspective from the commands side. All the commands I mentioned are documented, <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html> To supplement this part of the answer, you can loop through a bunch of PDB files in Python as outlined here: http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html You can determine the fraction of residues in helix and sheet with code like this: from chimera import openModels, Molecule #... inside the loop... for mol in openModels.list(modelTypes=[Molecule]): sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) # write them to a file with "print>>f" or to the reply log with just "print" The above assumes you have a little bit of familiarity with Python. I can provide more explanation if you need it. -Eric Eric Pettersen UCSF Computer Graphics Lab
I forget that in Python 2, division is “integer division” and truncates to an integer (unlike Python 3). So these lines: helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) need to be instead: helix_fract = len([r for r in mol.residues if r.isHelix]) / float(len(mol.residues)) sheet_fract = len([r for r in mol.residues if r.isSheet]) / float(len(mol.residues)) —Eric Eric Pettersen UCSF Computer Graphics Lab
On Oct 11, 2016, at 4:01 AM, Healey, Joe <J.R.J.Healey@warwick.ac.uk> wrote:
Nevermind, I think you can ignore my last email. Chimera wasn't recognising the 'isTurn' attribute so I guess that's my answer. I'll just define turn/other as 1-(everything else) which should suffice.
I've got the following based on your snippet, but for some reason it is giving me zeros for helix and turn:
chimera.openModels.open(args.infile,type="PDB")
with open(args.outfile, "w") as outputFile: for mol in openModels.list(modelTypes=[Molecule]): helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) other_fract = (1 - (helix_fract + sheet_fract)) print(args.infile + "\t" + str(helix_fract) + "\t" + str(sheet_fract) + "\t" + str(other_fract)) outputFile.write(args.infile + "\t" + str(helix_fract) + "\t" + str(sheet_fract) + "\t" + str(other_fract) + "\n")
What am I missing here?
Thanks
Joe
Joe Healey
M.Sc. B.Sc. (Hons) PhD Student MOAC CDT, Senate House University of Warwick Coventry CV47AL Mob: +44 (0) 7536 042620 | Email: J.R.J.Healey@warwick.ac.uk <mailto:J.R.J.Healey@warwick.ac.uk>
Jointly working in: Waterfield Lab <http://www2.warwick.ac.uk/fac/med/research/tsm/microinfect/staff/waterfieldl...> (WMS Microbiology and Infection Unit) and the Gibson Lab <http://www2.warwick.ac.uk/fac/sci/chemistry/research/gibson/gibsongroup/> (Warwick Chemistry)
Twitter: @JRJHealey <https://twitter.com/JRJHealey> | Website: MOAC Page <http://www2.warwick.ac.uk/fac/sci/moac/people/students/2013/joseph_healey> From: Eric Pettersen <pett@cgl.ucsf.edu> Sent: 10 October 2016 18:54:08 To: Healey, Joe Cc: chimera List Subject: Re: [Chimera-users] Computing 'basic' structure characteristics
On Oct 9, 2016, at 9:53 AM, Elaine Meng <meng@cgl.ucsf.edu <mailto:meng@cgl.ucsf.edu>> wrote:
If you just want to look at predominance of secondary structures, you would not use those integers which mean first strand, second strand, first helix, etc. Instead you could just see how many residues are already assigned as strand, helix, and coil. There aren’t commands to do this directly, only some very cumbersome approaches that I imagine are vastly inferior to using Python (like “select strand” and then writing a list of all those residues with “writesel” etc.).
I can’t help with the Python side, this is just the perspective from the commands side. All the commands I mentioned are documented, <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html <http://www.rbvi.ucsf.edu/chimera/docs/UsersGuide/framecommand.html>>
To supplement this part of the answer, you can loop through a bunch of PDB files in Python as outlined here:
http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html <http://www.cgl.ucsf.edu/chimera/docs/ProgrammersGuide/basicPrimer.html>
You can determine the fraction of residues in helix and sheet with code like this:
from chimera import openModels, Molecule
#… inside the loop… for mol in openModels.list(modelTypes=[Molecule]): sheet_fract = len([r for r in mol.residues if r.isSheet]) / len(mol.residues) helix_fract = len([r for r in mol.residues if r.isHelix]) / len(mol.residues) # write them to a file with “print>>f” or to the reply log with just “print”
The above assumes you have a little bit of familiarity with Python. I can provide more explanation if you need it.
—Eric
Eric Pettersen UCSF Computer Graphics Lab
participants (3)
-
 Elaine Meng
Elaine Meng -
 Eric Pettersen
Eric Pettersen -
 Healey, Joe
Healey, Joe